 Interesting problem I had to deal with today … Here’s the run-down:
Interesting problem I had to deal with today … Here’s the run-down:
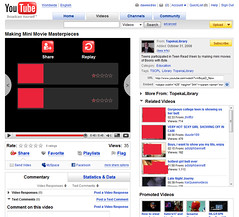
A month or so ago, some of my library’s teen patrons participated in a Making Mini Movie Masterpieces program held at my library. Cool program!
One of our librarians just posted the videos some of the teens made to YouTube … and guess what? In the related videos section of the video page (and also on the related videos flash thing that plays at the end of an embedded YouTube video), some … let’s just say “questionable” videos appeared.
Here’s what I think happened: YouTube found “similar” videos based on keywords. And the keywords it found in our video include these words in the title and description: mini teen teens. Dump those into YouTube and you’ll unfortunately find some pretty “interesting” videos.
Naturally, we don’t really want those thumbnails appearing on our library’s website, so we are fixing it in two ways:
- Good idea from our Web Developer: “There is an option when creating the embed code to include or not include links to “related” video. For this one I have gone ahead and embedded a new video without the related video thumbs at the end.”
- From me: Change the title of the video “Making Mini Movie Masterpieces” to something without the word “mini” (maybe just “Making Movie Masterpieces”) – and remove the “teen” and “teens” words in the description – maybe change them to “young adult.”
What an odd problem … and something you might want to be on the lookout for. Anyone else run into this type of problem, and if so – what did you do?
I know that I have a tendency to post videos and once they are online, kind of forget about them. Just shows how important it is to take a look at those settings and keywords before thinking the project is complete. Thanks for the heads up.
I know that I have a tendency to post videos and once they are online, kind of forget about them. Just shows how important it is to take a look at those settings and keywords before thinking the project is complete. Thanks for the heads up.
Same thing happened when we uploaded “Geek Out, Don’t Freak Out!” videos from ACPL. I think this is incredibly lame, but when viewing the video on YouTube’s site, there is no way to remove the related videos, except to flag them as inappropriate.
YouTube really needs to do something to address this problem. In the meantime, it is helpful to know that we can change the embedding code when we paste them into our blogs.
Same thing happened when we uploaded “Geek Out, Don’t Freak Out!” videos from ACPL. I think this is incredibly lame, but when viewing the video on YouTube’s site, there is no way to remove the related videos, except to flag them as inappropriate.
YouTube really needs to do something to address this problem. In the meantime, it is helpful to know that we can change the embedding code when we paste them into our blogs.
We had a similar problem with a video from our “No More Diapers” storytime. The word “diaper” brings up some similarly “interesting” videos in the Related Videos box. Even after removing the word “diaper” from the description and the title months and months ago, the same videos are showing up. Once related, always related, I suppose!
Between this and the kinds of comments we get on YouTube, I call it the Wild Wild West.
I wish that YouTube had safety levels, a la Flickr.
We had a similar problem with a video from our “No More Diapers” storytime. The word “diaper” brings up some similarly “interesting” videos in the Related Videos box. Even after removing the word “diaper” from the description and the title months and months ago, the same videos are showing up. Once related, always related, I suppose!
Between this and the kinds of comments we get on YouTube, I call it the Wild Wild West.
I wish that YouTube had safety levels, a la Flickr.
Sheesh, will you library folks never learn about how info and recommender systems work on the web?
Oh, and by the way, you know those adsense blocks you run on this blog…?
http://www.flickr.com/photos/psychemedia/3056407619/
Info literacy for the 21st c. is more than just card catalogues… 😉
Sheesh, will you library folks never learn about how info and recommender systems work on the web?
Oh, and by the way, you know those adsense blocks you run on this blog…?
http://www.flickr.com/photos/psychemedia/3056407619/
Info literacy for the 21st c. is more than just card catalogues… 😉
Tony – thanks for the comment. I get it (and I could care less about the adsense thing you pointed out). But many librarians aren’t skilled in 3rd party “recommender systems” – just the same as many corporate types, entrepreneurs, etc aren’t.
How about making a useful post on what we SHOULD be doing? Share your apparent knowledge…
Thanks!
Tony – thanks for the comment. I get it (and I could care less about the adsense thing you pointed out). But many librarians aren’t skilled in 3rd party “recommender systems” – just the same as many corporate types, entrepreneurs, etc aren’t.
How about making a useful post on what we SHOULD be doing? Share your apparent knowledge…
Thanks!
Hi David
I *know* you get it – (I just have a weird sense of humour…)
I guess the issue is one of “search and adsense consequences” or even “semantic web consequences”.
The web is increasingly dynamic, with content recommendation systems automatically annotating pages with advertising (in the sense of adsense etc), and in the blogosphere trackback/linkback engines picking up on links back to a post, and automatically generated “related links” being appended to the bottom of posts on e.g. hosted wordpress blogs.
Spamblog engines like wordpressdirect republish content found by searching for keywords, meaning your content could easily appear in a third party blog alongside content or ads you have no say over.
The long and the short of this is that publishing content now has consequences in the sense that once published the content may be automatically annotated, so an understanding of *how* that automated annotation happens becomes important.
Where the annotations are driven by ad engines, then it makes sense to look at content from an SEO point of view. SEO is about crafting content so that it does well on particular searches. If you assume that any post is by default, or “as if” optimised for some sort of search as a consequence of the way it is written, then it makes sense to know what sort of search it might be “as if” optimised for…?
So how about this? maybe we need a corollary to SEO, call it SEC – search engine consequences, which looks at content from the point of view of understanding what other content might become associated with it?
If you assume everything you publish on the web will be subject to simple term extraction or semantic term extraction, then in a sense it becomes a search query crafted around those terms that will potentially associate the results of that “emergent query” with the content itself.
One of the functions of the Library used to be classifying works so they could be discovered. Maybe now there is a need for understanding how machines will classify web published content so we can try to guard against “consequential annotations”?
For a long time I’ve thought one role for the Library going forwards is SEO – and raising the profile of the host institution’s content in the dominant search engines. But maybe an understanding of SEO is also necessary in a *defensive* capacity?
Hi David
I *know* you get it – (I just have a weird sense of humour…)
I guess the issue is one of “search and adsense consequences” or even “semantic web consequences”.
The web is increasingly dynamic, with content recommendation systems automatically annotating pages with advertising (in the sense of adsense etc), and in the blogosphere trackback/linkback engines picking up on links back to a post, and automatically generated “related links” being appended to the bottom of posts on e.g. hosted wordpress blogs.
Spamblog engines like wordpressdirect republish content found by searching for keywords, meaning your content could easily appear in a third party blog alongside content or ads you have no say over.
The long and the short of this is that publishing content now has consequences in the sense that once published the content may be automatically annotated, so an understanding of *how* that automated annotation happens becomes important.
Where the annotations are driven by ad engines, then it makes sense to look at content from an SEO point of view. SEO is about crafting content so that it does well on particular searches. If you assume that any post is by default, or “as if” optimised for some sort of search as a consequence of the way it is written, then it makes sense to know what sort of search it might be “as if” optimised for…?
So how about this? maybe we need a corollary to SEO, call it SEC – search engine consequences, which looks at content from the point of view of understanding what other content might become associated with it?
If you assume everything you publish on the web will be subject to simple term extraction or semantic term extraction, then in a sense it becomes a search query crafted around those terms that will potentially associate the results of that “emergent query” with the content itself.
One of the functions of the Library used to be classifying works so they could be discovered. Maybe now there is a need for understanding how machines will classify web published content so we can try to guard against “consequential annotations”?
For a long time I’ve thought one role for the Library going forwards is SEO – and raising the profile of the host institution’s content in the dominant search engines. But maybe an understanding of SEO is also necessary in a *defensive* capacity?
Tony – cool. Weird humor is always welcome here 🙂
Great comment, too – thanks for adding it! You’re right – I think it IS important to have that slightly defensive SEO understanding (I liked your “SEC”). The problem is SO HUGE though, because … at least at my library’s site … everyone needs this training. Not just the web dudes! In my example above, a youth services librarian posted the video – she has great training in helping kids and teens find stuff, in running successful programs for that age group … but probably not in SEO stuff. And how do you train for seemingly innocent words/phrases like “mini” or “teen?”
It even happens to me. I have a video up in youtube of me figuring out how to play harmonica. I titled it “learning blues harp.” And I have over 20,000 views, mostly of other people hunting for how to play a harmonica! They find me, then leave nasty little comments, like “wow – you’re as bad as me!” Well duh – I’m LEARNING it, for pete’s sake!
So one problem is that words can have more than one meaning (like learning or mini or teen), and then when that is dumped out of context (in context is on my videoblog, out of context is whenit’s hosted with millions of other videos on youtube), sometimes semantic “surprises” happen, I guess.
Either way – very interesting times to live and work in!
Tony – cool. Weird humor is always welcome here 🙂
Great comment, too – thanks for adding it! You’re right – I think it IS important to have that slightly defensive SEO understanding (I liked your “SEC”). The problem is SO HUGE though, because … at least at my library’s site … everyone needs this training. Not just the web dudes! In my example above, a youth services librarian posted the video – she has great training in helping kids and teens find stuff, in running successful programs for that age group … but probably not in SEO stuff. And how do you train for seemingly innocent words/phrases like “mini” or “teen?”
It even happens to me. I have a video up in youtube of me figuring out how to play harmonica. I titled it “learning blues harp.” And I have over 20,000 views, mostly of other people hunting for how to play a harmonica! They find me, then leave nasty little comments, like “wow – you’re as bad as me!” Well duh – I’m LEARNING it, for pete’s sake!
So one problem is that words can have more than one meaning (like learning or mini or teen), and then when that is dumped out of context (in context is on my videoblog, out of context is whenit’s hosted with millions of other videos on youtube), sometimes semantic “surprises” happen, I guess.
Either way – very interesting times to live and work in!
I’ve had the same annoying “similar videos” thing happen to me with a Happy Mother’s Day movie I created for my mom. I got a whole bunch of M I L F videos. I’m glad I checked before I sent the link to my 64 year-old mother. What a great way to introduce her to social networking. I solved the problem by taking it off YouTube, and embedding the video into a blog site I created just for the single purpose of sharing something with my mom.
I’ve had the same annoying “similar videos” thing happen to me with a Happy Mother’s Day movie I created for my mom. I got a whole bunch of M I L F videos. I’m glad I checked before I sent the link to my 64 year-old mother. What a great way to introduce her to social networking. I solved the problem by taking it off YouTube, and embedding the video into a blog site I created just for the single purpose of sharing something with my mom.
I think you’ll have similar problems with “young” and “adult.”
I like the SEC concept. I wonder if putting boring words like “library” in the text would have an effect? I searched youtube for “mini teen” and got what you’d expect. Then I searched “mini teen library” and your page was the first result. I see that you have “library” as a tag, but not in the text. I realize that this is the youtube search engine and not related videos, but maybe they are linked somehow.
I think you’ll have similar problems with “young” and “adult.”
I like the SEC concept. I wonder if putting boring words like “library” in the text would have an effect? I searched youtube for “mini teen” and got what you’d expect. Then I searched “mini teen library” and your page was the first result. I see that you have “library” as a tag, but not in the text. I realize that this is the youtube search engine and not related videos, but maybe they are linked somehow.